Business Textual Analysis#
You shall know a word by the company it keeps - J. R. Firth
Text mining techniques allow new insights to be extracted from unstructured text documents. We retrieve business descriptions text from 10-K filings, and use the Spacy NLP package for syntactic analysis, including part-of-speech tagging, named entity recognition and dependency parsing. Additionally, we explore dimentionality reduction techniques to visualize and cluster companies based on the relationships between business descriptions, represented as word embeddings, in a lower-dimensional space.
# By: Terence Lim, 2020-2025 (terence-lim.github.io)
import re
import numpy as np
from scipy import spatial
import pandas as pd
from pandas import DataFrame, Series
import matplotlib.pyplot as plt
import spacy
from sklearn import cluster
from sklearn.decomposition import PCA
from tqdm import tqdm
from finds.database import SQL, RedisDB
from finds.structured import CRSP, BusDay
from finds.unstructured import Edgar
from finds.utils import Store, Finder, ColorMap
from secret import credentials, paths
# %matplotlib qt
VERBOSE = 0
sql = SQL(**credentials['sql'], verbose=VERBOSE)
user = SQL(**credentials['user'], verbose=VERBOSE)
bd = BusDay(sql)
rdb = RedisDB(**credentials['redis'])
crsp = CRSP(sql, bd, rdb, verbose=VERBOSE)
ed = Edgar(paths['10X'], zipped=True, verbose=VERBOSE)
store = Store(paths['scratch'])
find = Finder(sql)
begdate, enddate = 20240101, 20241231
Retrieve the usual investment universe and retain only the largest size decile (based on NYSE market cap breakpoints).
# Retrieve universe of stocks
univ = crsp.get_universe(bd.endmo(begdate, -1))
comnam = crsp.build_lookup('permno', 'comnam', fillna="") # company name
univ['comnam'] = comnam(univ.index)
ticker = crsp.build_lookup('permno', 'ticker', fillna="") # tickers
univ['ticker'] = ticker(univ.index)
Extract Business Description text from 10-K filings.
# retrieve business decriptions from 10K's
item, form = 'bus10K', '10-K'
rows = DataFrame(ed.open(form=form, item=item))
found = rows[rows['permno'].isin(univ.index[univ.decile <= 1]) # largest decile only
& rows['date'].between(begdate, enddate)]\
.drop_duplicates(subset=['permno'], keep='last')\
.set_index('permno')
Syntactic analysis#
Syntactic analysis examines the roles of words in sentences and how they combine to form phrases and larger linguistic structures. This process helps model relationships such as subject-verb-object dependencies, which are fundamental for NLP tasks like dependency and constituent parsing.
SpaCy#
spaCy is a widely used open-source Python library for advanced NLP tasks, including POS tagging, named entity recognition (NER), and dependency parsing. It provides pre-trained models for various languages and domains, as well as customizable pipelines for processing text data.
# ! python -m spacy download en_core_web_sm
nlp = spacy.load("en_core_web_lg")
Lemmatization#
Lemmatization reduces a word to its base or dictionary form (lemma), representing its morphological root.
# Using spaCy pipeline to tokenize NVIDIA's 10-K business description text
nvidia = find('NVIDIA')['permno'].iloc[0]
doc = nlp(ed[found.loc[nvidia, 'pathname']][:nlp.max_length].lower())
tokens = DataFrame.from_records([{'text': token.text,
'lemma': token.lemma_,
'alpha': token.is_alpha,
'stop': token.is_stop,
'punct': token.is_punct}
for token in doc], index=range(len(doc)))
tokens.head(30)
| text | lemma | alpha | stop | punct | |
|---|---|---|---|---|---|
| 0 | item | item | True | False | False |
| 1 | 1 | 1 | False | False | False |
| 2 | . | . | False | False | True |
| 3 | business | business | True | False | False |
| 4 | \n\n | \n\n | False | False | False |
| 5 | our | our | True | True | False |
| 6 | company | company | True | False | False |
| 7 | \n\n | \n\n | False | False | False |
| 8 | nvidia | nvidia | True | False | False |
| 9 | pioneered | pioneer | True | False | False |
| 10 | accelerated | accelerate | True | False | False |
| 11 | computing | computing | True | False | False |
| 12 | to | to | True | True | False |
| 13 | help | help | True | False | False |
| 14 | solve | solve | True | False | False |
| 15 | the | the | True | True | False |
| 16 | most | most | True | True | False |
| 17 | challenging | challenging | True | False | False |
| 18 | computational | computational | True | False | False |
| 19 | problems | problem | True | False | False |
| 20 | . | . | False | False | True |
| 21 | nvidia | nvidia | True | False | False |
| 22 | is | be | True | True | False |
| 23 | now | now | True | True | False |
| 24 | a | a | True | True | False |
| 25 | full | full | True | True | False |
| 26 | - | - | False | False | True |
| 27 | stack | stack | True | False | False |
| 28 | computing | computing | True | False | False |
| 29 | infrastructure | infrastructure | True | False | False |
Part-of-speech#
Part-of-speech (POS) tagging assigns grammatical categories (e.g., noun, verb, adjective) to words in a text corpus. This aids in understanding sentence structure and extracting meaning by identifying the roles of words within sentences.
tags = DataFrame.from_records([{'text': token.text,
'pos': token.pos_,
'tag': token.tag_,
'dep': token.dep_}
for token in doc], index=range(len(doc)))
tags.head(30)
| text | pos | tag | dep | |
|---|---|---|---|---|
| 0 | item | NOUN | NN | ROOT |
| 1 | 1 | NUM | CD | nummod |
| 2 | . | PUNCT | . | punct |
| 3 | business | NOUN | NN | nsubj |
| 4 | \n\n | SPACE | _SP | dep |
| 5 | our | PRON | PRP$ | poss |
| 6 | company | NOUN | NN | appos |
| 7 | \n\n | SPACE | _SP | dep |
| 8 | nvidia | PROPN | NNP | appos |
| 9 | pioneered | VERB | VBD | ROOT |
| 10 | accelerated | VERB | VBD | xcomp |
| 11 | computing | NOUN | NN | dobj |
| 12 | to | PART | TO | aux |
| 13 | help | VERB | VB | advcl |
| 14 | solve | VERB | VB | xcomp |
| 15 | the | DET | DT | det |
| 16 | most | ADV | RBS | advmod |
| 17 | challenging | ADJ | JJ | amod |
| 18 | computational | ADJ | JJ | amod |
| 19 | problems | NOUN | NNS | dobj |
| 20 | . | PUNCT | . | punct |
| 21 | nvidia | PROPN | NNP | nsubj |
| 22 | is | AUX | VBZ | ROOT |
| 23 | now | ADV | RB | advmod |
| 24 | a | DET | DT | det |
| 25 | full | ADJ | JJ | amod |
| 26 | - | PUNCT | HYPH | punct |
| 27 | stack | NOUN | NN | compound |
| 28 | computing | NOUN | NN | compound |
| 29 | infrastructure | NOUN | NN | compound |
Named entity recognition#
Named Entity Recognition (NER) identifies and categorizes named entities (e.g., people, organizations, locations, dates) in text. This process helps classify textual data into meaningful categories.
ents = DataFrame.from_records([{'text': ent.text,
'label': ent.label_,
'start': ent.start_char,
'end': ent.end_char}
for ent in doc.ents], index=range(len(doc.ents)))
ents.head(20)
| text | label | start | end | |
|---|---|---|---|---|
| 0 | 1 | CARDINAL | 5 | 6 |
| 1 | nvidia | PERSON | 133 | 139 |
| 2 | as well as hundreds | CARDINAL | 352 | 371 |
| 3 | healthcare | ORG | 853 | 863 |
| 4 | tens of thousands | CARDINAL | 1012 | 1029 |
| 5 | gpu | ORG | 1033 | 1036 |
| 6 | gpu | ORG | 1239 | 1242 |
| 7 | today | DATE | 1347 | 1352 |
| 8 | thousands | CARDINAL | 1498 | 1507 |
| 9 | gpu | ORG | 1771 | 1774 |
| 10 | thousands | CARDINAL | 1819 | 1828 |
| 11 | gpus | GPE | 2594 | 2598 |
| 12 | multi-billion-dollar | MONEY | 2708 | 2728 |
| 13 | third | ORDINAL | 2849 | 2854 |
| 14 | over 45.3 billion | MONEY | 3100 | 3117 |
| 15 | gpu | ORG | 3248 | 3251 |
| 16 | 1999 | DATE | 3255 | 3259 |
| 17 | 2006 | DATE | 3391 | 3395 |
| 18 | gpu | ORG | 3451 | 3454 |
| 19 | 2012 | DATE | 3557 | 3561 |
# Entity Visualizer
from spacy import displacy
displacy.render(doc[:300], style="ent", jupyter=True)
our company
nvidia pioneered accelerated computing to help solve the most challenging computational problems. nvidia PERSON is now a full-stack computing infrastructure company with data-center-scale offerings that are reshaping industry.
our full-stack includes the foundational cuda programming model that runs on all nvidia gpus, as well as hundreds CARDINAL of domain-specific software libraries, software development kits, or sdks, and application programming interfaces, or apis. this deep and broad software stack accelerates the performance and eases the deployment of nvidia accelerated computing for computationally intensive workloads such as artificial intelligence, or ai, model training and inference, data analytics, scientific computing, and 3d graphics, with vertical-specific optimizations to address industries ranging from healthcare ORG and telecom to automotive and manufacturing.
our data-center-scale offerings are comprised of compute and networking solutions that can scale to tens of thousands CARDINAL of gpu ORG -accelerated servers interconnected to function as a single giant computer; this type of data center architecture and scale is needed for the development and deployment of modern ai applications.
the gpu ORG was initially used to simulate human imagination, enabling the virtual worlds of video games and films. today DATE , it also simulates human intelligence, enabling a deeper understanding of the physical world. its parallel processing capabilities, supported by thousands CARDINAL of computing cores, are essential for deep learning algorithms. this form of ai, in which software writes itself by learning from large amounts of data, can serve as the brain of computers, robots and self-driving cars that can perceive and understand the
Dependency parsing#
Dependency parsing determines grammatical relationships between words in a sentence, representing these relationships as a tree structure where each word (except the root) depends on another word (its head). This technique helps identify syntactic roles, such as subjects, objects, and modifiers.
Transition-based parsing algorithms uses a set of transition operations (e.g. shift, reduce) to incrementally build a dependency tree from an input sentence.
Unlike dependency parsing, constituent parsing focuses on identifying and representing the hierarchical structure of phrases in a sentence based on formal grammar rules. It groups words into nested syntactic units (e.noun phrases and verb phrases) and represents them in a tree structure.
The CKY (Cocke-Kasami-Younger) algorithm is a dynamic programming technique used for parsing sentences and constructing parse trees.
Probabilistic Context-Free Grammar (PCFG) extends standard Context-Free Grammar (CFG) by assigning probabilities to production rules, indicating the likelihood of specific grammatical structures. Each rule defines how non-terminal symbols (e.g., NP for noun phrase) expand into words or other non-terminals, guiding sentence generation and parsing.
Models for automatic tagging and parsing rely on labeled datasets known as treebanks, which contain syntactically annotated sentences. The Penn Treebank is a widely used treebank for English, providing annotations for POS tags and parse trees.
sentence_spans = list(doc.sents)
displacy.render(sentence_spans[2:4], style="dep", jupyter=True,
options=dict(compact=False, distance=175))
Semantic similarity#
Word vectors#
Word vectors are numerical representations of words in a multidimensional space, learned from their co-occurrence patterns in large text corpora. Words with similar syntactic and semantic meanings tend to have vector representations that are close together in this space.
For example, spaCy’s en_core_web_lg model represents over 500,000 words using 300-dimensional vectors.
Extract lemmatized noun forms from business descriptions using spaCy’s POS tagger:
# Extract nouns
bus = {}
for permno in tqdm(found.index):
doc = nlp(ed[found.loc[permno, 'pathname']][:nlp.max_length].lower())
nouns = " ".join([re.sub("[^a-zA-Z]+", "", token.lemma_) for token in doc
if token.pos_ in ['NOUN'] and len(token.lemma_) > 2])
if len(nouns) > 100:
bus[permno] = nouns
store['business'] = bus
100%|██████████| 192/192 [03:12<00:00, 1.00s/it]
bus = store.load('business')
permnos = list(bus.keys())
tickers = univ.loc[permnos, 'ticker'].to_list()
Compute the average word vector for NVIDIA’s business description text:
# example of word vector
vec1 = nlp(bus[nvidia]).vector
vec1
array([-0.5495549 , 0.0522468 , -0.70095205, 1.1134154 , 2.659689 ,
0.29627848, 1.3154105 , 3.8272932 , -2.232087 , -1.3053178 ,
6.069174 , 2.0604212 , -4.542866 , 2.3177896 , -1.1287518 ,
2.3917935 , 3.1968606 , 1.5996909 , -2.3438275 , 0.03434967,
0.22686806, 1.7824569 , -2.384547 , 0.8608239 , -1.2319311 ,
-1.774604 , -1.8425854 , -1.7403452 , -0.7102895 , 1.0869901 ,
1.2046682 , 1.2530138 , -1.1417824 , -0.4984767 , 0.34321743,
-0.37546915, 1.4804035 , 0.8114897 , 1.3119912 , 0.38791072,
0.25189775, -0.1770816 , 0.1785395 , 1.0146813 , -1.4704382 ,
1.6199547 , 2.021769 , -1.9505422 , 0.4602281 , -1.281002 ,
0.07107421, 2.3507724 , -0.18837918, -3.80177 , -0.54604673,
0.5786306 , -1.7812697 , 1.5003949 , 0.40720284, -1.5742034 ,
2.2474368 , 1.2563457 , -2.2915537 , -1.2388986 , 2.408017 ,
1.9807013 , -2.2583349 , -3.3942797 , 0.5241013 , 3.0477126 ,
-0.97571445, 0.7010974 , -1.2003129 , 0.38448045, -0.30499592,
1.3931054 , -1.3777359 , 0.99693114, -1.8231292 , -0.1508515 ,
-2.595402 , -0.6554817 , 0.96918464, 1.4329529 , -0.2420673 ,
-0.08297056, -1.2713333 , -1.8489853 , 0.77105236, -0.235054 ,
-1.2015461 , 1.0783287 , 1.5740684 , -2.2493582 , 0.43573543,
-0.56152374, 0.58803385, -0.5924455 , 0.8756682 , 1.2502667 ,
3.0838132 , 0.3415912 , 1.887193 , 1.8639498 , 0.2804779 ,
4.218261 , -1.1121116 , -1.805579 , -0.22270828, -2.56832 ,
2.4099169 , -0.22422643, -1.1543158 , 0.06765282, 0.83664316,
1.7835015 , -2.6237123 , -1.3570241 , -0.46247697, -2.476458 ,
-1.9124763 , -2.6474092 , 0.44025388, 1.1519567 , -0.42653838,
-2.8462713 , 0.2980864 , -2.9798195 , 2.9588706 , -1.819657 ,
-2.464192 , 0.32522804, 3.3010955 , 0.7937097 , -0.15216802,
-0.42828757, -0.9942988 , -0.44921628, 1.9312432 , 0.28458852,
-0.6386989 , -0.87969756, -0.13129689, 0.85792863, 1.7823339 ,
0.16759728, -3.5592077 , -0.2112106 , 0.06164274, 3.368905 ,
-0.3132938 , 1.2434231 , 0.21065742, 1.2389091 , -0.66589624,
0.5398899 , 2.8091311 , 1.7358444 , -0.91453594, -2.6195803 ,
-0.9402572 , -1.2330531 , 0.71588945, 1.699086 , -1.72446 ,
-1.1087135 , -2.044233 , 0.5116665 , 0.7511035 , -1.510701 ,
-1.5667175 , -0.22543517, -0.37966043, 0.95050013, 2.100138 ,
1.966492 , 0.6108724 , -0.31808442, -1.9397378 , -1.2919445 ,
-1.7783433 , 1.7884035 , 1.1175009 , -1.9068832 , -1.0304377 ,
0.6533309 , -0.94094557, -1.4831365 , 1.5252017 , 1.73394 ,
0.05441582, -1.1678139 , 0.10588835, -1.8394533 , 1.820474 ,
0.70712596, -2.8049684 , -0.1084957 , 0.5009497 , -0.05614741,
-0.74415725, -1.0815455 , -0.28300503, -1.0312603 , 3.5577624 ,
0.81285644, -3.4548876 , 1.3007482 , -0.0527516 , -1.5823797 ,
0.94375974, 0.01696876, -1.1761798 , 2.141124 , 0.8728857 ,
1.7190704 , 2.6591263 , -4.227103 , -0.5748424 , 0.36368647,
-1.838823 , 1.3353976 , -1.5363356 , -0.98404247, -0.64337295,
-2.6795921 , 0.4494206 , 2.0296626 , 1.1337993 , -0.15482494,
2.2946403 , -2.6738138 , -1.2725773 , 1.763216 , 2.8063855 ,
0.46778396, -0.36578366, -0.26262623, 0.9403954 , 1.0015386 ,
-2.0167701 , -1.1006184 , -0.1618742 , 0.9444055 , -0.27051136,
0.33339593, -1.7367964 , 1.3408182 , 0.32765946, 1.1382856 ,
0.6616231 , -1.8980618 , -3.5863128 , -2.049999 , 0.11113743,
-2.0100012 , 0.91014284, -1.1377766 , 0.30864185, 0.8823487 ,
-1.5351313 , 4.9388237 , 1.6379622 , 1.251249 , 1.8976227 ,
-0.77638566, -0.17837228, 1.8998926 , -0.8797592 , -0.77389985,
-0.19354557, -0.14190447, 0.15318388, -1.0070832 , 0.3741701 ,
-2.8941076 , 0.9670155 , -1.7984045 , -1.1186454 , 1.0722593 ,
3.4040382 , 0.38004097, 1.4921545 , -0.0391783 , 3.8353264 ,
0.2084171 , 1.266672 , 1.8079621 , -2.3702457 , -0.04794558,
0.3776366 , -0.42777508, -0.809167 , 0.7592459 , -1.5167016 ,
0.2553154 , 1.1878173 , -2.2171407 , -0.76328766, 2.2422533 ],
dtype=float32)
Compute the average word vector for all companies’ business descriptions:
# Compute sentence vectors
vecs = np.array([nlp(bus[permno]).vector for permno in bus.keys()])
store['vectors'] = vecs
vecs = store['vectors']
# Distance matrix
n = len(bus)
distances = np.zeros((n, n))
for row in range(n):
for col in range(row, n):
distances[row, col] = spatial.distance.cosine(vecs[row], vecs[col])
distances[col, row] = distances[row, col]
Identify companies with the most similar business descriptions:
def most_similar(p):
dist = distances[permnos.index(p)]
dist[permnos.index(p)] = max(dist) # to ignore own distance
return univ.loc[permnos[np.argmin(dist)]]
for name in ['NVIDIA', 'APPLE COMPUTER', 'JNJ', 'EXXON MOBIL', 'AMERICAN EXPRESS']:
p = find(name)['permno'].iloc[-1]
print(f"{most_similar(p)['comnam']}' is most similar to '{name}'")
QUALCOMM INC' is most similar to 'NVIDIA'
SALESFORCE INC' is most similar to 'APPLE COMPUTER'
PFIZER INC' is most similar to 'JNJ'
PIONEER NATURAL RESOURCES CO' is most similar to 'EXXON MOBIL'
U S BANCORP DEL' is most similar to 'AMERICAN EXPRESS'
Dimensionality reduction#
t-SNE visualization#
T-distributed Stochastic Neighbor Embedding (t-SNE) visualizes high-dimensional data by converting similarities between points into joint probabilities and minimizing the Kullback-Leibler divergence between the high-dimensional and lower-dimensional representations. t-SNE preserves local structures, making it effective for clustering and uncovering hidden patterns in business descriptions.
from sklearn.manifold import TSNE
Z = TSNE(n_components=2, perplexity=10, random_state=42)\
.fit_transform(vecs)
Reduce business description vectors to 2D using t-SNE and label points with ticker symbols:
fig, ax = plt.subplots(figsize=(10, 8))
ax.scatter(Z[:, 0], Z[:, 1], color="C0", alpha=.3)
for text, x, y in zip(tickers, Z[:, 0], Z[:, 1]):
ax.annotate(text=text, xy=(x, y), fontsize='small')
ax.set_title(f"t-SNE visualization of largest decile stocks ({enddate//10000})")
plt.tight_layout()
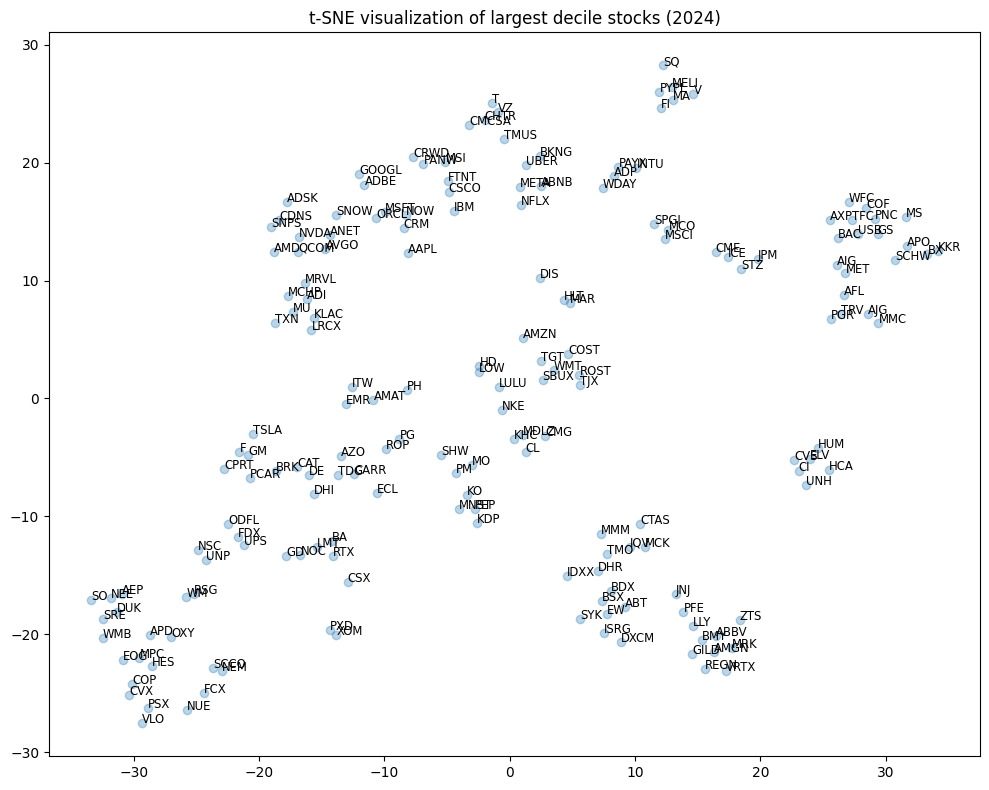
DBSCAN clustering#
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is an unsupervised clustering algorithm that detects clusters of varying densities and identifies outliers. Unlike k-means, it does not require a predefined number of clusters. Instead, it uses two parameters: epsilon (ε) and the minimum number of points required to form a dense region.
# eps is the most important parameter for DBSCAN
eps = 4
db = cluster.DBSCAN(eps=eps) # default eps
db.fit(Z)
n_clusters = len(set(db.labels_).difference({-1}))
n_noise = np.sum(db.labels_ == -1)
DataFrame(dict(clusters=n_clusters, noise=n_noise, eps=eps), index=['DBSCAN'])
| clusters | noise | eps | |
|---|---|---|---|
| DBSCAN | 12 | 19 | 4 |
Visualize DBSCAN clusters in 2D space. Display outlier ticker symbols with larger font sizes:
cmap = ColorMap(n_clusters)
fig, ax = plt.subplots(figsize=(10, 8))
# plot core samples with larger marker size
ax.scatter(Z[db.core_sample_indices_, 0],
Z[db.core_sample_indices_, 1],
c=cmap[db.labels_[db.core_sample_indices_]],
alpha=.1, s=100, edgecolors=None)
# plot non-core samples with smaller marker size
non_core = np.ones_like(db.labels_, dtype=bool)
non_core[db.core_sample_indices_] = False
non_core[db.labels_ < 0] = False
ax.scatter(Z[non_core, 0], Z[non_core, 1], c=cmap[db.labels_[non_core]],
alpha=.1, s=20, edgecolors=None)
# plot noise samples
ax.scatter(Z[db.labels_ < 0, 0], Z[db.labels_ < 0, 1], c="darkgrey",
alpha=.5, s=20, edgecolors=None)
# annotate with tickers not in core samples
for i, (t, c, xy) in enumerate(zip(tickers, db.labels_, Z)):
if i in db.core_sample_indices_:
ax.annotate(text=t, xy=xy+.5, color=cmap[c], fontsize='xx-small')
elif c == -1:
ax.annotate(text=t, xy=xy+.5, color='black', fontsize='medium')
else:
ax.annotate(text=t, xy=xy+.5, color=cmap[c], fontsize='medium')
ax.set_title(f"Largest decile stocks ({enddate//10000})")
plt.tight_layout()
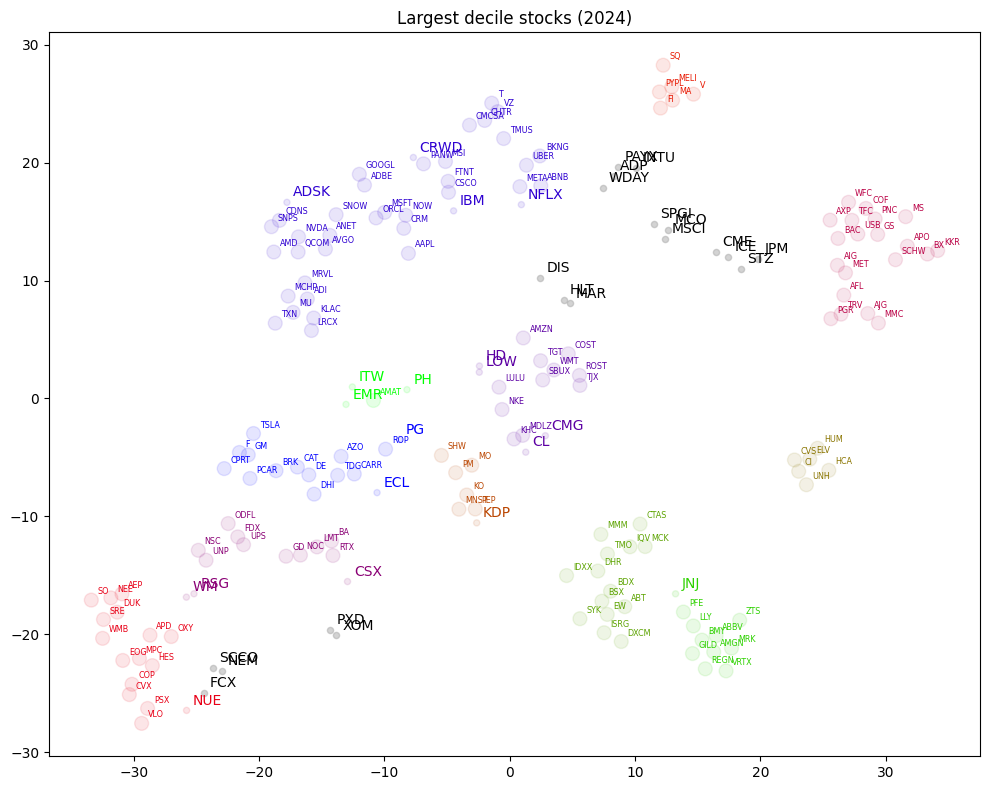
List companies tagged as noisy samples:
print("Samples tagged as noise:")
univ.loc[np.array(permnos)[db.labels_ < 0]].sort_values('naics')
Samples tagged as noise:
| cap | capco | decile | nyse | siccd | prc | naics | comnam | ticker | |
|---|---|---|---|---|---|---|---|---|---|
| permno | |||||||||
| 75241 | 5.246653e+07 | 5.246653e+07 | 1 | True | 1311 | 224.88 | 211120 | PIONEER NATURAL RESOURCES CO | PXD |
| 21207 | 4.770164e+07 | 4.770164e+07 | 1 | True | 1041 | 41.39 | 212220 | NEWMONT CORP | NEM |
| 81774 | 6.104440e+07 | 6.104440e+07 | 1 | True | 1021 | 42.57 | 212230 | FREEPORT MCMORAN INC | FCX |
| 82800 | 6.654158e+07 | 6.654158e+07 | 1 | True | 1021 | 86.07 | 212230 | SOUTHERN COPPER CORP | SCCO |
| 69796 | 4.440053e+07 | 4.440053e+07 | 1 | True | 2084 | 241.75 | 312130 | CONSTELLATION BRANDS INC | STZ |
| 11850 | 4.005332e+08 | 4.005332e+08 | 1 | True | 2911 | 99.98 | 324110 | EXXON MOBIL CORP | XOM |
| 78975 | 1.749684e+08 | 1.749684e+08 | 1 | False | 7370 | 625.03 | 513210 | INTUIT INC | INTU |
| 26403 | 1.652592e+08 | 1.652592e+08 | 1 | True | 4833 | 90.29 | 516120 | DISNEY WALT CO | DIS |
| 44644 | 9.568078e+07 | 9.568078e+07 | 1 | False | 7374 | 232.97 | 518210 | AUTOMATIC DATA PROCESSING INC | ADP |
| 47896 | 4.917605e+08 | 4.917605e+08 | 1 | True | 6021 | 170.10 | 522110 | JPMORGAN CHASE & CO | JPM |
| 90993 | 7.350871e+07 | 7.350871e+07 | 1 | True | 6231 | 128.43 | 523210 | INTERCONTINENTALEXCHANGE GRP INC | ICE |
| 89626 | 7.565405e+07 | 7.565405e+07 | 1 | False | 6200 | 210.60 | 523210 | C M E GROUP INC | CME |
| 17478 | 1.395567e+08 | 1.395567e+08 | 1 | True | 6282 | 440.52 | 523930 | S & P GLOBAL INC | SPGI |
| 61621 | 4.285840e+07 | 4.285840e+07 | 1 | False | 8700 | 119.11 | 541219 | PAYCHEX INC | PAYX |
| 13628 | 5.769654e+07 | 5.769654e+07 | 1 | False | 7372 | 276.06 | 541511 | WORKDAY INC | WDAY |
| 48506 | 7.147248e+07 | 7.147248e+07 | 1 | True | 7323 | 390.56 | 561450 | MOODYS CORP | MCO |
| 92402 | 4.473782e+07 | 4.473782e+07 | 1 | True | 7389 | 565.65 | 561499 | M S C I INC | MSCI |
| 85913 | 6.551968e+07 | 6.551968e+07 | 1 | False | 7011 | 225.51 | 721110 | MARRIOTT INTERNATIONAL INC NEW | MAR |
| 14338 | 4.669516e+07 | 4.669516e+07 | 1 | True | 7011 | 182.09 | 721110 | HILTON WORLDWIDE HOLDINGS INC | HLT |
UMAP vizualization#
UMAP (Uniform Manifold Approximation and Projection) is a dimensionality reduction technique that constructs a high-dimensional graph of data points and optimizes a lower-dimensional representation while preserving essential relationships. Compared to t-SNE, UMAP is faster, scales better for large datasets, and retains more global structure.
import umap
Z = umap.UMAP(n_components=2, n_jobs=1, min_dist=0.0, random_state=42)\
.fit_transform(vecs)
fig, ax = plt.subplots(figsize=(10, 8))
ax.scatter(Z[:, 0], Z[:, 1], color="C0", alpha=.3)
for text, x, y in zip(tickers, Z[:, 0], Z[:, 1]):
ax.annotate(text=text, xy=(x, y), fontsize='small')
ax.set_title(f"UMAP visualization of largest decile stocks ({enddate//10000})")
plt.tight_layout()
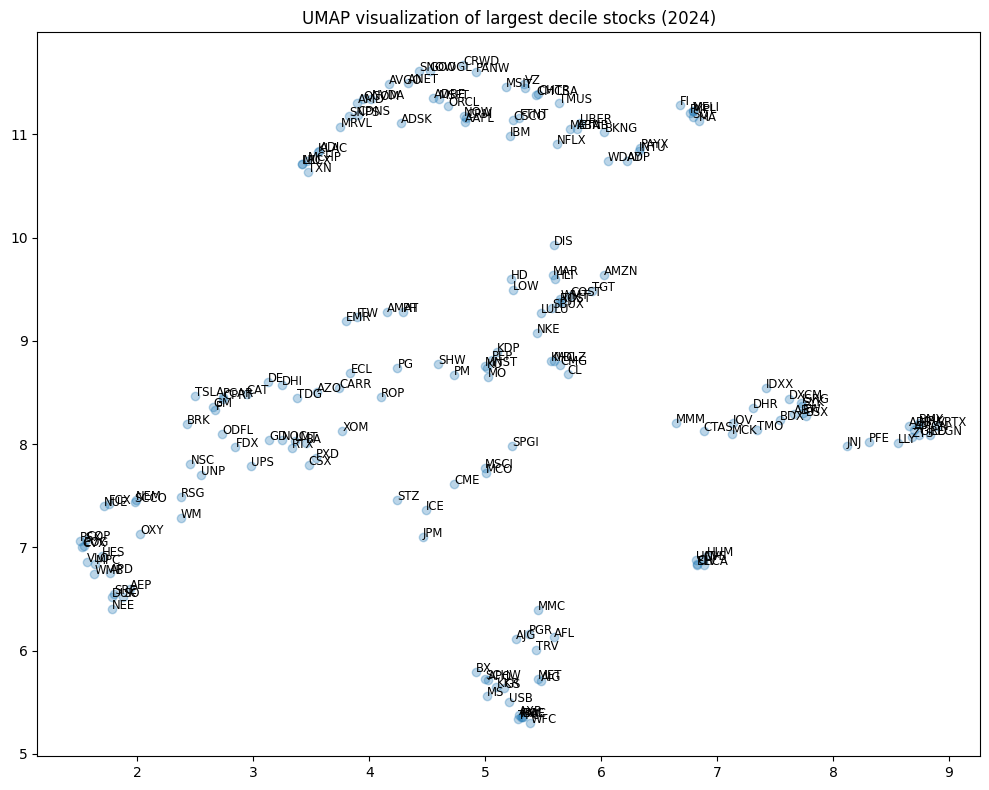
HDBSCAN clustering#
HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) extends DBSCAN by varying the epsilon parameter and optimizing cluster stability. This makes it more robust to variations in density and parameter selection.
# eps is the most important parameter for DBSCAN
hdb = cluster.HDBSCAN()
hdb.fit(Z)
n_clusters = len(set(hdb.labels_).difference({-1}))
n_noise = np.sum(hdb.labels_ == -1)
DataFrame(dict(clusters=n_clusters, noise=n_noise), index=['HDBSCAN'])
| clusters | noise | |
|---|---|---|
| HDBSCAN | 14 | 32 |
Visualize HDBSCAN clusters in 2D space. Display outlier ticker symbols with larger font sizes.
cmap = ColorMap(n_clusters)
fig, ax = plt.subplots(figsize=(10, 8))
# plot core samples with larger marker size
ax.scatter(Z[hdb.labels_ >= 0, 0],
Z[hdb.labels_ >= 0, 1],
c=cmap[hdb.labels_[hdb.labels_ >= 0]],
alpha=.1, s=100, edgecolors=None)
# plot noise samples
ax.scatter(Z[hdb.labels_ < 0, 0], Z[hdb.labels_ < 0, 1], c="darkgrey",
alpha=.5, s=20, edgecolors=None)
# annotate with tickers not in core samples
for i, (t, c, xy) in enumerate(zip(tickers, hdb.labels_, Z)):
if c >= 0:
ax.annotate(text=t, xy=xy+.01, color=cmap[c], fontsize='xx-small')
else:
ax.annotate(text=t, xy=xy+.01, color="black", fontsize='medium')
ax.set_title(f"Largest decile stocks ({enddate//10000})")
plt.tight_layout()
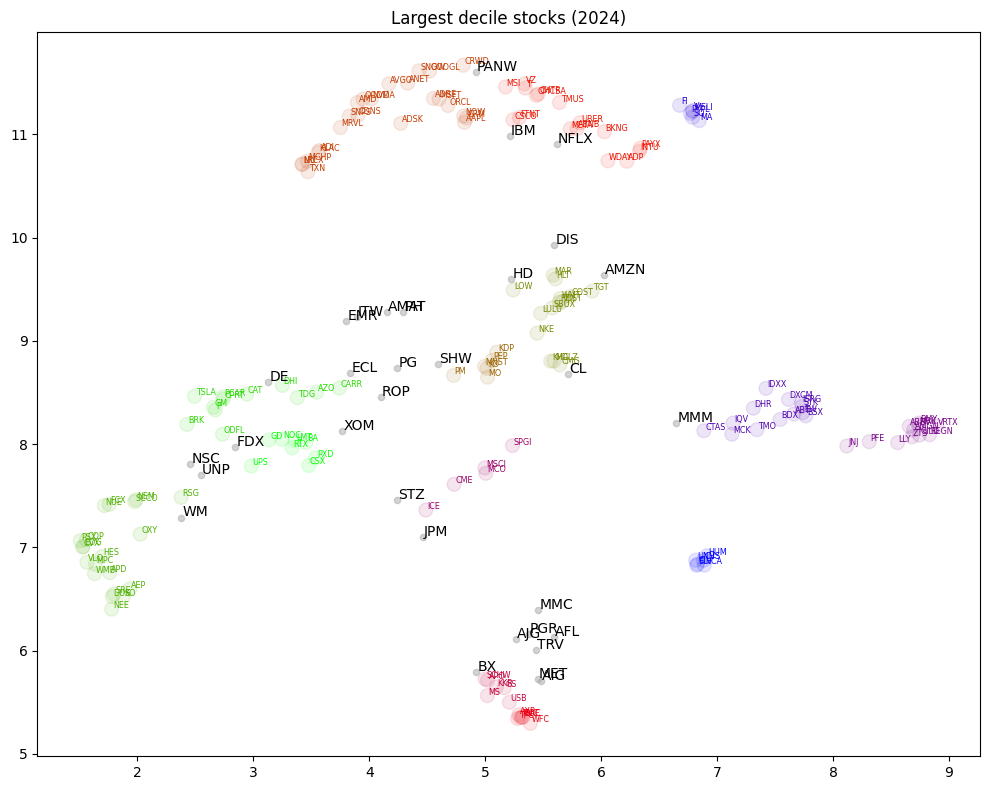
List companies tagged as noisy samples
print("Samples tagged as noise:")
univ.loc[np.array(permnos)[hdb.labels_ < 0]].sort_values('naics')
Samples tagged as noise:
| cap | capco | decile | nyse | siccd | prc | naics | comnam | ticker | |
|---|---|---|---|---|---|---|---|---|---|
| permno | |||||||||
| 69796 | 4.440053e+07 | 4.440053e+07 | 1 | True | 2084 | 241.75 | 312130 | CONSTELLATION BRANDS INC | STZ |
| 11850 | 4.005332e+08 | 4.005332e+08 | 1 | True | 2911 | 99.98 | 324110 | EXXON MOBIL CORP | XOM |
| 36468 | 7.983580e+07 | 7.983580e+07 | 1 | True | 2851 | 311.90 | 325510 | SHERWIN WILLIAMS CO | SHW |
| 70578 | 5.655752e+07 | 5.655752e+07 | 1 | True | 2841 | 198.35 | 325611 | ECOLAB INC | ECL |
| 18163 | 3.453781e+08 | 3.453781e+08 | 1 | True | 2844 | 146.54 | 325620 | PROCTER & GAMBLE CO | PG |
| 18729 | 6.563098e+07 | 6.563098e+07 | 1 | True | 2844 | 79.71 | 325620 | COLGATE PALMOLIVE CO | CL |
| 22103 | 5.548783e+07 | 5.548783e+07 | 1 | True | 3491 | 97.33 | 332911 | EMERSON ELECTRIC CO | EMR |
| 19350 | 1.120656e+08 | 1.120656e+08 | 1 | True | 3523 | 399.87 | 333111 | DEERE & CO | DE |
| 14702 | 1.345954e+08 | 1.345954e+08 | 1 | False | 3550 | 162.07 | 333248 | APPLIED MATERIALS INC | AMAT |
| 41355 | 5.918889e+07 | 5.918889e+07 | 1 | True | 3593 | 460.70 | 333995 | PARKER HANNIFIN CORP | PH |
| 56573 | 7.881408e+07 | 7.881408e+07 | 1 | True | 3569 | 261.94 | 333999 | ILLINOIS TOOL WORKS INC | ITW |
| 12490 | 1.493406e+08 | 1.493406e+08 | 1 | True | 3571 | 163.55 | 334111 | INTERNATIONAL BUSINESS MACHS COR | IBM |
| 77338 | 5.827867e+07 | 5.827867e+07 | 1 | False | 3823 | 545.17 | 334513 | ROPER TECHNOLOGIES INC | ROP |
| 22592 | 6.037929e+07 | 6.037929e+07 | 1 | True | 3841 | 109.32 | 339112 | 3M CO | MMM |
| 66181 | 3.449080e+08 | 3.449080e+08 | 1 | True | 5211 | 346.55 | 444110 | HOME DEPOT INC | HD |
| 84788 | 1.556169e+09 | 1.556169e+09 | 1 | False | 7370 | 151.94 | 454110 | AMAZON COM INC | AMZN |
| 48725 | 1.497292e+08 | 1.497292e+08 | 1 | True | 4011 | 245.62 | 482111 | UNION PACIFIC CORP | UNP |
| 64311 | 5.345403e+07 | 5.345403e+07 | 1 | True | 4731 | 236.38 | 488510 | NORFOLK SOUTHERN CORP | NSC |
| 60628 | 6.321543e+07 | 6.321543e+07 | 1 | True | 4513 | 252.97 | 492110 | FEDEX CORP | FDX |
| 26403 | 1.652592e+08 | 1.652592e+08 | 1 | True | 4833 | 90.29 | 516120 | DISNEY WALT CO | DIS |
| 47896 | 4.917605e+08 | 4.917605e+08 | 1 | True | 6021 | 170.10 | 522110 | JPMORGAN CHASE & CO | JPM |
| 92108 | 9.302455e+07 | 9.302455e+07 | 1 | True | 6282 | 130.92 | 523940 | BLACKSTONE INC | BX |
| 87842 | 4.894876e+07 | 4.894876e+07 | 1 | True | 6311 | 66.13 | 524113 | METLIFE INC | MET |
| 57904 | 4.821135e+07 | 4.821135e+07 | 1 | True | 6321 | 82.50 | 524114 | AFLAC INC | AFL |
| 59459 | 4.350773e+07 | 4.350773e+07 | 1 | True | 6331 | 190.49 | 524126 | TRAVELERS COMPANIES INC | TRV |
| 64390 | 9.318533e+07 | 9.318533e+07 | 1 | True | 6331 | 159.28 | 524126 | PROGRESSIVE CORP OH | PGR |
| 66800 | 4.756321e+07 | 4.756321e+07 | 1 | True | 6331 | 67.75 | 524126 | AMERICAN INTERNATIONAL GROUP INC | AIG |
| 38093 | 4.855159e+07 | 4.855159e+07 | 1 | True | 6411 | 224.88 | 524210 | GALLAGHER ARTHUR J & CO | AJG |
| 45751 | 9.342235e+07 | 9.342235e+07 | 1 | True | 6411 | 189.47 | 524210 | MARSH & MCLENNAN COS INC | MMC |
| 89393 | 2.107022e+08 | 2.107022e+08 | 1 | False | 7841 | 486.88 | 532282 | NETFLIX INC | NFLX |
| 13511 | 9.297566e+07 | 9.297566e+07 | 1 | False | 7371 | 294.88 | 541511 | PALO ALTO NETWORKS INC | PANW |
| 11955 | 7.213700e+07 | 7.213700e+07 | 1 | True | 4953 | 179.10 | 562219 | WASTE MANAGEMENT INC DEL | WM |
References:
Greg Durrett, 2023, “CS388 Natural Language Processing course materisl”, retrieved from https://www.cs.utexas.edu/~gdurrett/courses/online-course/materials.html
Text-Based Network Industries and Endogenous Product Differentiation. Gerard Hoberg and Gordon Phillips, 2016, Journal of Political Economy 124 (5), 1423-1465.
Product Market Synergies and Competition in Mergers and Acquisitions: A Text-Based Analysis. Gerard Hoberg and Gordon Phillips, 2010, Review of Financial Studies 23 (10), 3773-3811.